One of the big decisions you have to make whenever you create a new virtual guest is deciding the size and type of the VHD. It might seem a trivial decision at first, and maybe you just click on the default options and create a dynamic 127Gb VHD, either on purpose, by mistake, because you were in a hurry, or by ignorance. Maybe you just found it there, because someone else created it and you have to deal with it now.
Whatever the case, and after some time has passed, you might actually realize that the amount of virtual storage assigned to it is far away from being used. For example, maybe it is a dynamic expansion 127Gb VHD and after a year or two of usage, you see that its usage has leveraged at around 20Gb. You might think, well that's not an issue, it doesn't matter. Since it is a dynamic expansion VHD, it will grow whenever you need it, but if you actually see the .vhd file, it is sized much more that the expected 20Gb, it might be sized 80 or 90Gb, despite the fact that it has never reached that usage.
In a recent case, I faced a Windows Server 2008 Hyper-V host with 32Gb of RAM, 16 cores, running 10 virtual machines (Windows 2003 and 2008 mostly), and a couple of Ubuntu virtual servers, one of them used for running Cacti (whose graphics will be shown here).
The virtual hard disk files (.vhd files) were stored on a physical (RAID 1) 750Gb hard disk shown below.
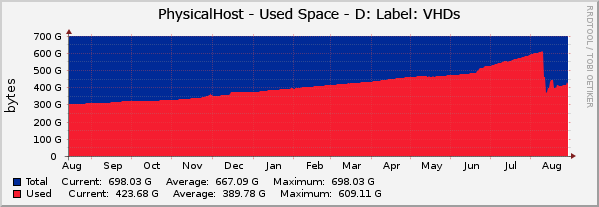 |
| Evolution of hard disk usage in the host's drive containing the .vhd files |
As you can see in the graph, the usage of this drive in the host has been growing and growing for a year, with an increase in the slope at the end of June. The problem was that almost all 10 virtual machines where defined with the default 127Gb dynamic expansion hard disks. If they would ever fill up their 127Gb of space that would mean 1270Gb of physical hard disk required in a 750Gb drive, which would be quite difficult to handle... ;)
The funny thing was that none of them ever used over 40Gb. That would mean 10 x 40Gb = 400Gb of expected usage in the host but it was, however, running out of physical space. What was happening?
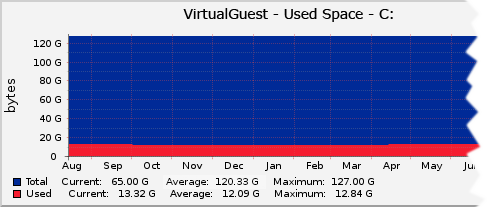 |
| None of the 10 virtual guests had ever used more than 40Gb of their VHD space. |
If you want the short version: blame on dynamic expansion. If you ever need to use dynamic expansion, be sure to define a small VHD, i.e. 10 or 20Gb will be enough, since a dynamic expansion VHD can be easily enlaged using Hyper-V built-in tools (Edit → Expand → Select new size → Finish).
If you want the long one, keep on reading.
How dynamic expansion Virtual Hard Disks work?
A dynamic expansion VHD is created differently as a fixed size VHD. The latter uses 100% of its size in the host from the creation time. That means that as long as you create a 127Gb fixed size VHD you will be losing 127Gb of your host's physical space because the .vhd file is sized 127Gb right from the start (even though it does not contain any data at all yet). There is a direct 1:1 correspondence between each byte in the .vhd file (from the host point of view) and its place inside the VHD (from the guest point of view), so that the host do not need to make any 'translation' when the guest requests a particular information from its VHD: The host does a simple calculation and knows exactly what point inside the .vhd file needs to read/written (because everything is defined beforehand, since it is a fixed size VHD, the order of the data is as simple as 1, 2, 3, ...).However when you create a dynamic expansion VHD, it is initially very small in size, no matter the virtual maximum size you assigned to it. This is because the only content actually written it is a table of 'translations' for every cluster (or equivalent) and its order (placement) inside the .vhd file. So, whenever a read/write is requested by the guest, the host needs to do an extra step and read that table to see where inside the .vhd file the requested bytes should be read from/written to. Simply because they were not created at VHD creation time, but on the fly during the life of the guest, and their order is not known beforehand.
Furthermore, when a file is deleted in the guest, the .vhd file in the host does not get smaller. The host only marks that zone of the .vhd file as free in that translation table. It might (or not) be used again when more space is needed. That's why you only see your .vhd file grow and grow and if you want to shrink it you have to set the guest offline and do it manually using Hyper-V built-in tools (Edit → Compact). This operation rearranges the valid data inside the .vhd file freeing the space occupied by not used sectors (but still using space inside the .vhd file).
Warning: Do not ever install a defragger inside a guest, since moving data from one part of the VHD disk to another will only make the .vhd file bigger in the host. That was what happened at the end of June and that is the reason of the increased slope in the former graph. Someone installed a defragger in thinking it might help in the performance, whilst the results were just the opposite.
And now that the .vhd files are soooo big... how do I shrink them?
You cannot automatically shrink a .vhd file using Hyper-V built-in tools, but there is manual procedure you can follow:
How to shrink a VHD file? How do I make a VHD smaller?
1. Install a defragger on the guest (despite I advised you not to do it) and set it to 'everything off' (no real-time nor automatic defragging, so that it only runs manually when you need it to). Select the defragger of your choice, but make sure it has a feature called 'Prep for shrink' or something equivalent, which moves all data towards the beginning of the disk, as much as possible, despite it might produce fragmentation.
2. Run one or two passes using this 'Prep for shrink' defragmentation mode (in particular I use a 30 day trial of Raxco PerfectDisk 12 Server (or WorkStation if you are not shrinking a Server VHD), that you can uninstall after you have followed the following steps). You can download the trial from http://www.raxco.com/business/server.aspx

3. Make a boot-time defragmentation and make sure that the paging file (pagefile.sys) has been moved also towards the beginning of the disk. If not the case, configure the system so that it does NOT use page file at all and then let Windows decide the size of it. Doing so, we make sure the page file is deleted and created again (hopefully, nearer to the beginning of the disk).
4. (Optional) Execute a Zero Fill Free Space. In our case, we did not run it and we were still able to reduce the .vhd file.
5. Stop the virtual guest and compact its .vhd file, through Hyper-V built-in tools (Edit → Compact).
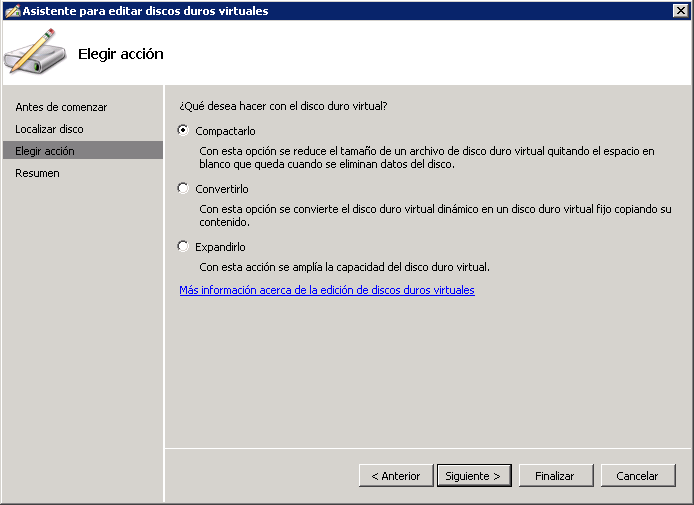
6. Start Disk Management snapin and click Action → Attach VHD and specify the location of the already compacted .vhd file. Be sure not to mount it in read-only mode.
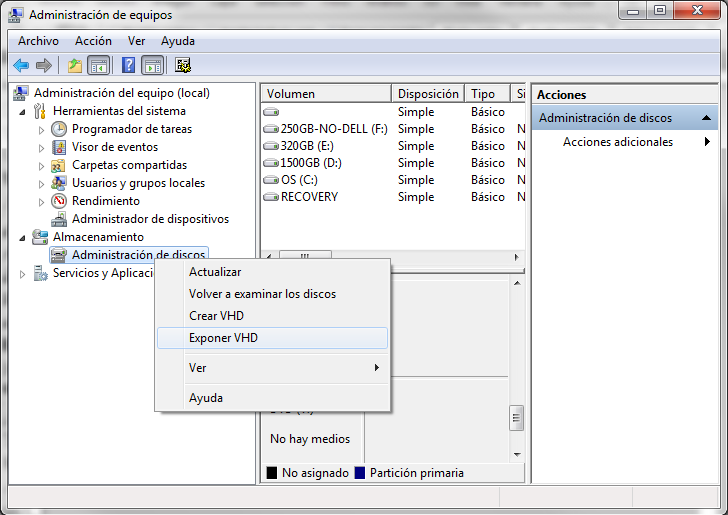
7. Right click on it and select 'Reduce volume'. A message telling that volume is being checked in order to calculate the limits is shown. Please wait. When the checks had finished you are shown a dialog with the limits the .vhd can be reduced. Leave the default values as they are and click 'Reduce'. You can do that from inside Windows 2008 Server with Hyper-V itself, or do it by copying the .vhd file to a Windows 7 computer (Windows 7 can also reduce the volume).
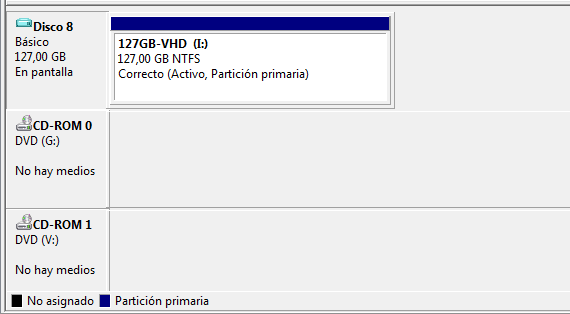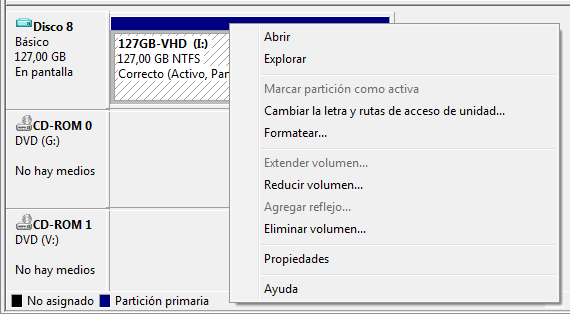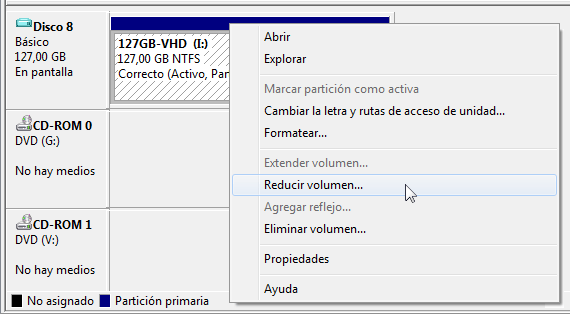
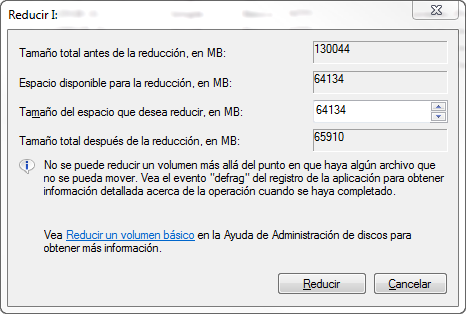
8. When the process has finished, unmount the VHD (right click and select Hide VHD). Now we have a VHD with unassigned space (the partition does not fill 100% of the VHD).
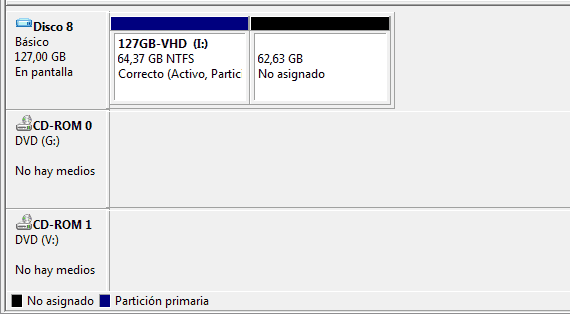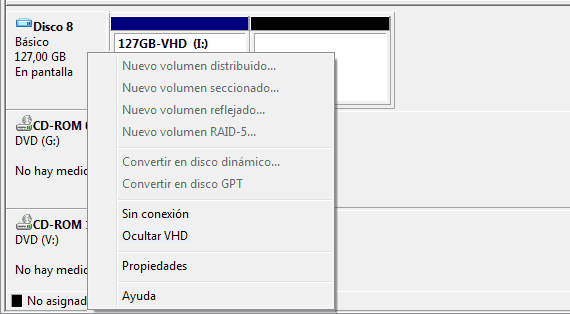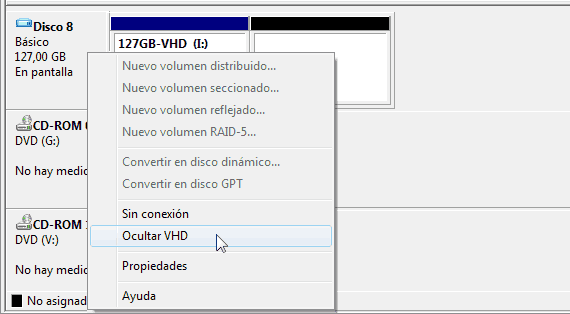
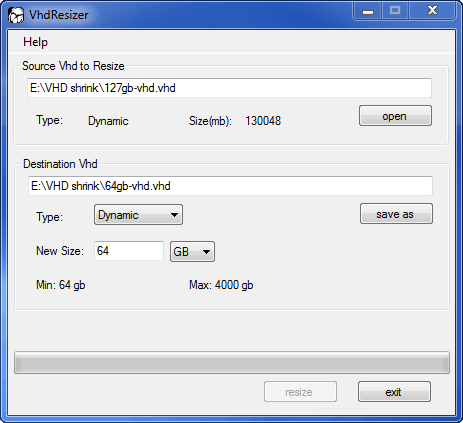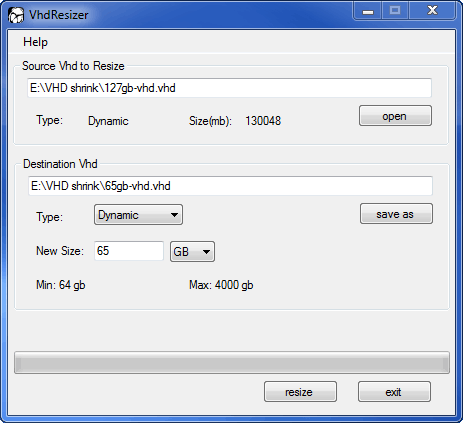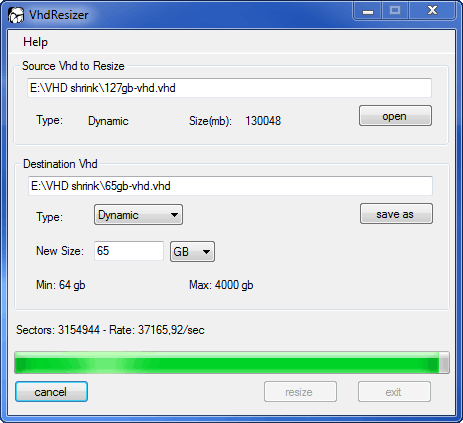
9. Run VHD Resizer and select the .vhd file. Write a different name for the output shrinked .vhd file. VHD Resizer checks the .vhd file and shows you the minimum size that the destination .vhd can be. Be sure to write (at least) that minimum value plus one or Resize button will remain disabled. Click on Resize and wait for the process to complete.
10. Modify the properties of the Virtual Guest so that it uses the new shrinked .vhd file instead of the original one, that you can keep for a proper retention period as a backup. Then start the virtual guest and check the size of the VHD.
11. (Optional) If you open Disk Management inside the virtual guest, you will see that there is some free unassigned space in the shrinked VHD. You can retrieve them and make the volume a bit bigger right clicking on it and selecting 'Extend volume'. By doing that the VHD will be shown exactly as the same Gb in size that you specified in step 9.
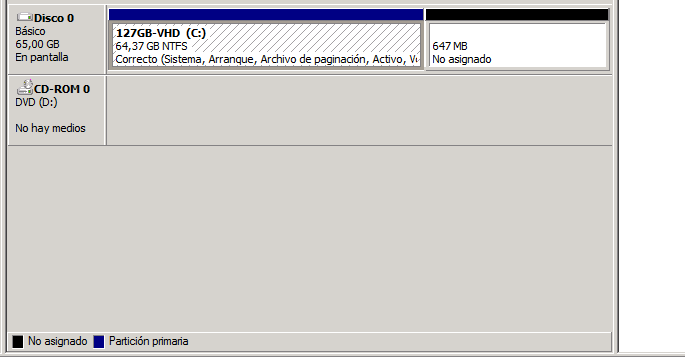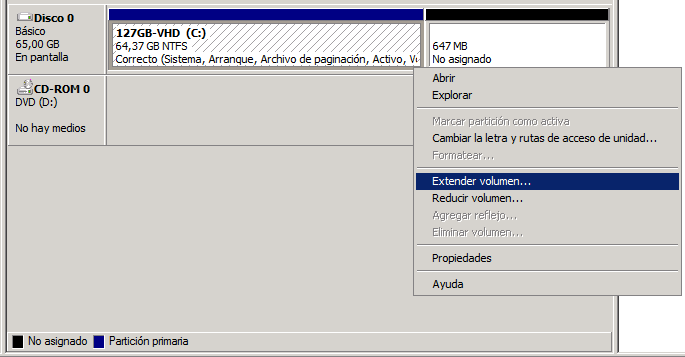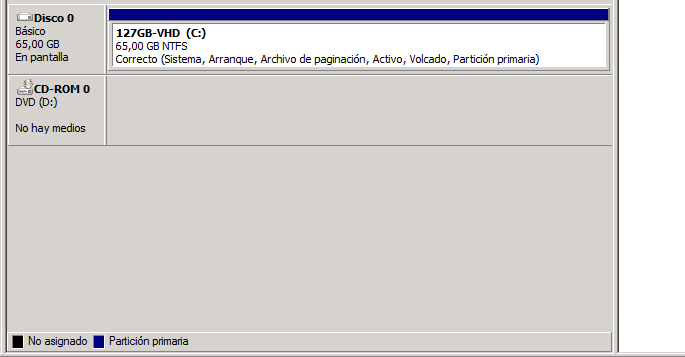
Note: I have not been able to shrink any VHD to less than half its initial size. In my cases they were 127Gb VHD with dynamic expansion and I managed to leave them at 65Gb only. That is because during the original installation of the virtual OS (Windows), there are some unmovable metadata files that are written at the middle of the disk: $Bitmap, $LogFile, $MFT, $MFTMirr and $Secure (in my case).
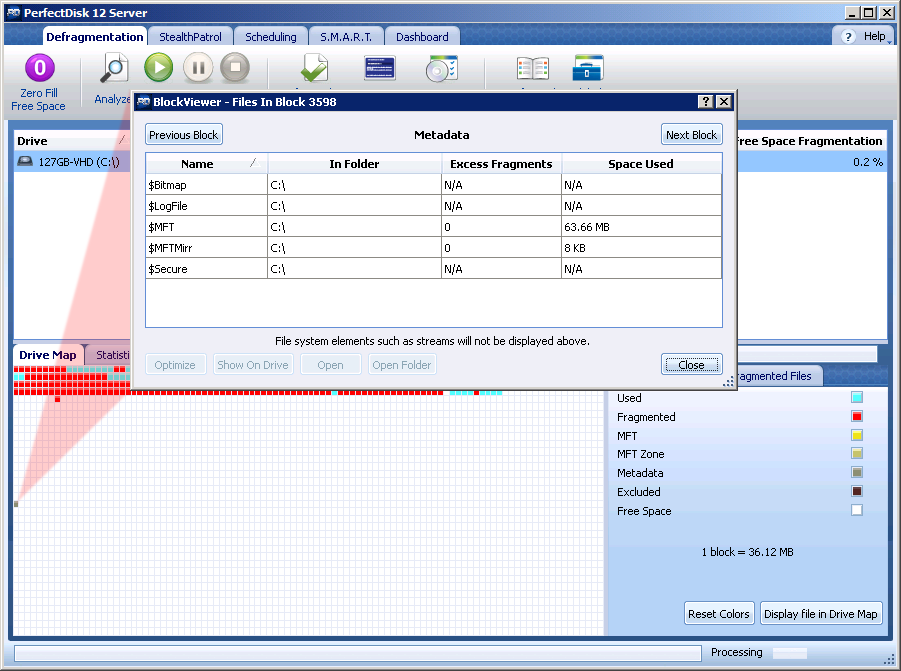
Since they cannot be moved elsewhere in the VHD during the Prep-for-shrink step (2), they are the only limiting factor to a greater reduction in the VHD shrink process.




 Support")